Написано: 07.12.2022
Перекодировка из UTF-8 в Cp-1251.
Написать функцию для перекодировки строки из UTF-8 в Cp-1251.
Стандартная функция
UtfToAnsi()
Алгоритм
Перекодировка осуществляется по следующему алгоритму:
- Проверяем, что последовательность представляет собой uft-8 (старший октет начинается с битов 110).
- Определяем последовательность байт, из которых состоит текущий символ (байты в последовательности имеют старшие биты 10).
- Отбрасываем маркерные биты и сдвигаем байты вправо на размер отброшенных битов.
- Полученное число представляет собой символ Unicode.
- Преобразуем символ Unicode в символ Cp1251.
Пример
Нужно преобразовать символ ‘Д’.
В Utf-8 будет код 0xD0 0x94 (1101.0000.1001.0100).

Отбрасываем маркерные биты (выделены зелёным).

и сдвигаем биты старшего байта (вправо на два, на количество отброшенных бит младшего байта, сдвигаемые биты помечены серым цветом):

получаем 0000.0100.0001.0100. Это символ Unicode 0x414

Пример преобразования 3-х байтового символа.
Нужно преобразовать символ ‘№’.
В Utf-8 будет код 0xE2 0x84 0x96 (1110.0010.1000.0100.1001.0110)

Отбрасываем маркерные биты (выделены зелёным).

Выполняем сдвиг (сдвигаемые биты помечены розовым и серым цветом).

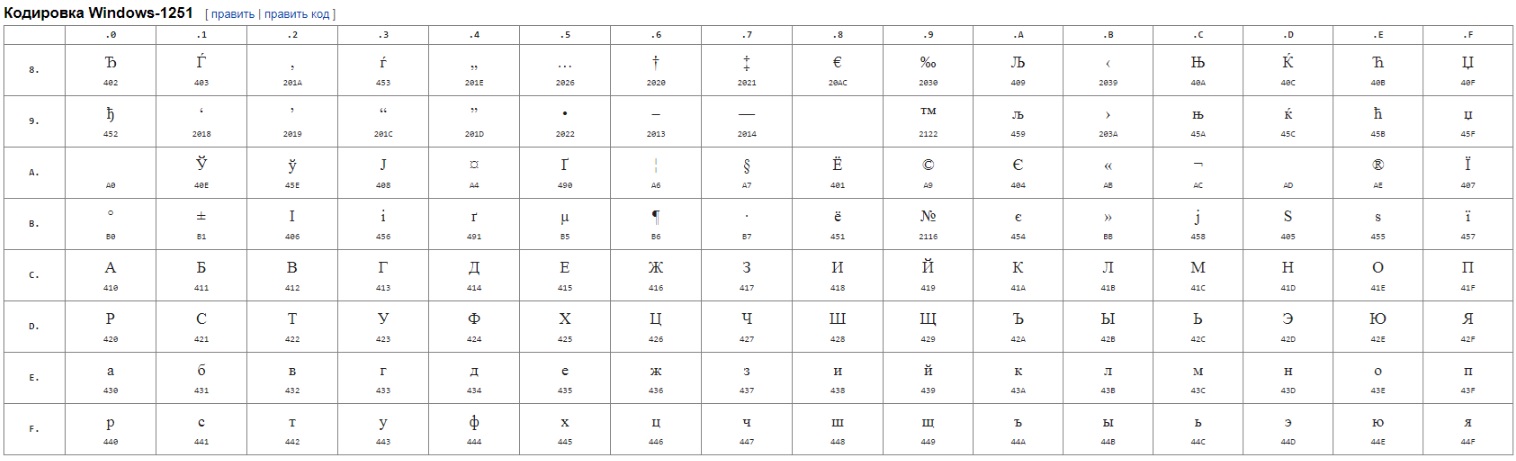
Получаем 0010.0001.0001.0110. Это символ Unicode 0x2116. То есть ‘№’. В кодировке Windows-1251 – 0xB9.
Кодировка Windows-1251.
Функция Utf8ToCp1251()
AnsiString __fastcall osopo_func::Utf8ToCp1251(AnsiString X)
{
AnsiString R;
std::stringstream ss;
const char * s = X.c_str();
char Ch;
int i, j, l, stop = 0;
unsigned short n;
unsigned char b[4];
try {
// проход по строке, символы по одному копируются в std::stringstream
for(i = 0; s[i] != '\0'; i++) {
if((s[i] & 0xC0) != 0xC0) {
// не utf-8
ss << s[i];
} else {
// если utf-8
j = 0;
// первый байт встреченной последовательности запоминаем в массиве b, префикс '110' отсекается
b[0] = s[i] & 0x1F;
// разбираем последующие байты вида '10xx xxxx'
do {
j += 1;
if(s[i+j] == '\0') {
// на всякий случай, если встретится конец строки, выйдем
return ss.str().c_str();
}
// запоминаются в массиве, отсекая префиксы '10'
b[j] = s[i+j] & 0x3F;
// повторяем до тех пор, пока идут байты '10xx xxxx'
} while ((s[i+j+1] & 0xC0) == 0x80);
// теперь байты сдвигаются вправо на величину префикса
// то есть нужно от предыдущего байта нужно взять 2 младших бита
// и записать их в старшие биты нашего байта
l = j;
while(j > 0) {
b[j] |= (b[j-1] & 0x03) << 6;
b[j-1] >>= 2;
j -= 1;
}
if(l == 1) {
// 2-х байтовая последовательность utf-8
n = (b[0] << 8) | b[1];
} else {
n = 0;
}
// теперь у нас в n -- символ Unicode
if(n >= 0x410 && n <= 0x44F) {
// если это кириллица, перекодируем в cp-1251
Ch = (0xC0 + (unsigned char)(n - 0x410));
ss << Ch;
}
i += l;
}
}
R = ss.str().c_str();
} catch(...) {}
return R;
}