Часть 9. Лучшие практики построения образов
Сканирование системы безопасности
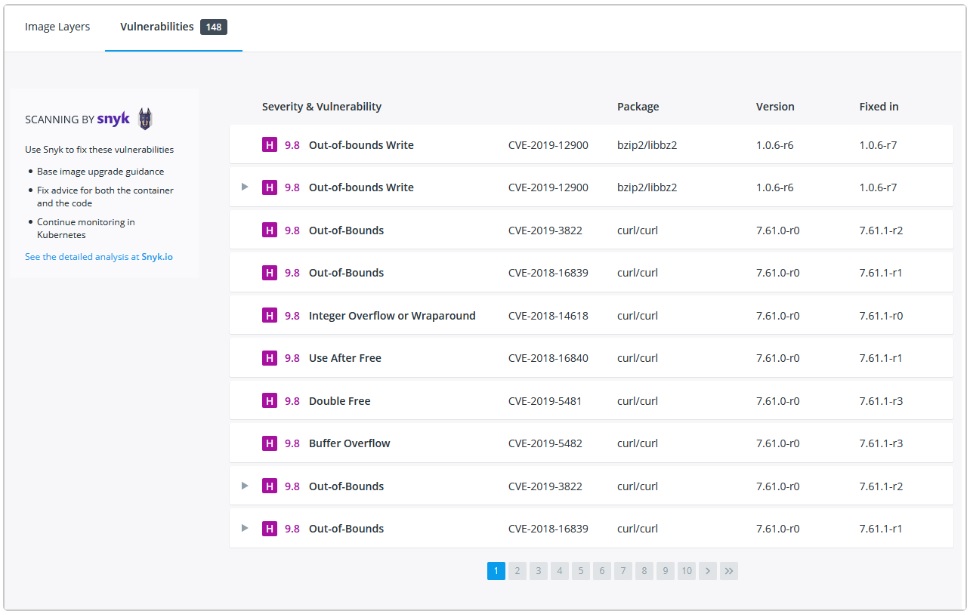
После создания образа рекомендуется проверить его на наличие уязвимостей в системе безопасности с помощью команды docker scan. Docker сотрудничает со Snyk для предоставления сервиса сканирования уязвимостей.
Примечание
Вы должны войти в аккаунт на Docker Hub, чтобы сканировать свои изображения. Запустите командуdocker scan --login, а затем отсканируйте свои изображения с помощьюdocker scan <имя изображения>.
Например, чтобы отсканировать изображение getting-started, созданное ранее в руководстве, вы можете просто ввести
docker scan getting-started
При сканировании используется постоянно обновляемая база данных уязвимостей, поэтому результаты, которые вы видите, будут меняться по мере обнаружения новых уязвимостей, но это может выглядеть примерно так:
✗ Low severity vulnerability found in freetype/freetype
Description: CVE-2020-15999
Info: https://snyk.io/vuln/SNYK-ALPINE310-FREETYPE-1019641
Introduced through: freetype/freetype@2.10.0-r0, gd/libgd@2.2.5-r2
From: freetype/freetype@2.10.0-r0
From: gd/libgd@2.2.5-r2 > freetype/freetype@2.10.0-r0
Fixed in: 2.10.0-r1
✗ Medium severity vulnerability found in libxml2/libxml2
Description: Out-of-bounds Read
Info: https://snyk.io/vuln/SNYK-ALPINE310-LIBXML2-674791
Introduced through: libxml2/libxml2@2.9.9-r3, libxslt/libxslt@1.1.33-r3, nginx-module-xslt/nginx-module-xslt@1.17.9-r1
From: libxml2/libxml2@2.9.9-r3
From: libxslt/libxslt@1.1.33-r3 > libxml2/libxml2@2.9.9-r3
From: nginx-module-xslt/nginx-module-xslt@1.17.9-r1 > libxml2/libxml2@2.9.9-r3
Fixed in: 2.9.9-r4
В выходных данных указан тип уязвимости, URL-адрес для получения дополнительной информации и, что важно, какая версия соответствующей библиотеки устраняет уязвимость.
Есть несколько других вариантов, о которых можно прочитать в документации docker scan.
Помимо сканирования только что созданного образа в командной строке, вы также можете настроить Docker Hub на автоматическое сканирование всех вновь загруженных изображений, после чего вы сможете просмотреть результаты как в Docker Hub, так и в Docker Desktop.
Слои изображений
Знаете ли вы, что вы можете посмотреть на то, что составляет изображение? Используя команду docker image history, можно просмотреть команду, которая использовалась для создания каждого слоя в изображении.
1. Используйте команду docker image history, чтобы просмотреть слои в изображении getting-started, созданном ранее в руководстве.
docker image history getting-started
Вы должны получить выходные данные, которые выглядят примерно так (даты / идентификаторы могут отличаться).
IMAGE CREATED CREATED BY SIZE COMMENT
a78a40cbf866 18 seconds ago /bin/sh -c #(nop) CMD ["node" "src/index.j… 0B
f1d1808565d6 19 seconds ago /bin/sh -c yarn install --production 85.4MB
a2c054d14948 36 seconds ago /bin/sh -c #(nop) COPY dir:5dc710ad87c789593… 198kB
9577ae713121 37 seconds ago /bin/sh -c #(nop) WORKDIR /app 0B
b95baba1cfdb 13 days ago /bin/sh -c #(nop) CMD ["node"] 0B
<missing> 13 days ago /bin/sh -c #(nop) ENTRYPOINT ["docker-entry… 0B
<missing> 13 days ago /bin/sh -c #(nop) COPY file:238737301d473041… 116B
<missing> 13 days ago /bin/sh -c apk add --no-cache --virtual .bui… 5.35MB
<missing> 13 days ago /bin/sh -c #(nop) ENV YARN_VERSION=1.21.1 0B
<missing> 13 days ago /bin/sh -c addgroup -g 1000 node && addu… 74.3MB
<missing> 13 days ago /bin/sh -c #(nop) ENV NODE_VERSION=12.14.1 0B
<missing> 13 days ago /bin/sh -c #(nop) CMD ["/bin/sh"] 0B
<missing> 13 days ago /bin/sh -c #(nop) ADD file:e69d441d729412d24… 5.59MB
Каждая строка представляет собой слой изображения. На дисплее здесь показана основа внизу с самым новым слоем вверху. Используя это, вы также можете быстро увидеть размер каждого слоя, помогая диагностировать большие изображения.
2. Вы заметите, что некоторые строки усечены. Если вы добавите флаг --no-trunc, вы получите полный вывод (да … забавно, как вы используете усеченный флаг для получения необрезанного вывода, да?)
docker image history --no-trunc getting-started
Кэширование слоев
Теперь, когда вы увидели многослойность в действии, вам следует усвоить важный урок, который поможет сократить время сборки изображений-контейнеров.
Как только слой изменяется, все нижестоящие слои нужно также пересобрать заново
Давайте посмотрим на файл Dockerfile, который мы уже использовали
# syntax=docker/dockerfile:1
FROM node:18-alpine
WORKDIR /app
COPY . .
RUN yarn install --production
CMD ["node", "src/index.js"]
Возвращаясь к выводу истории изображений, мы видим, что каждая команда в Dockerfile становится новым слоем в изображении. Возможно, вы помните, что когда мы вносили изменения в изображение, зависимости yarn пришлось переустановить. Есть ли способ это исправить? Нет особого смысла отправлять одни и те же зависимости каждый раз, когда производится сборка, верно?
Чтобы исправить это, нам нужно реструктурировать наш файл Dockerfile, чтобы помочь поддерживать кэширование зависимостей. Для приложений, основанных на Node.js, эти зависимости определены в файле package.json. Итак, что, если мы сначала скопируем только этот файл, установим зависимости, а затем скопируем все остальное? Затем мы воссоздаем зависимости yarn только в том случае, если в package.json были внесены изменения. Есть смысл?
1. Измените Dockerfile, чтобы сначала скопировать package.json, установить зависимости, а затем скопировать остальное.
# syntax=docker/dockerfile:1
FROM node:18-alpine
WORKDIR /app
COPY package.json yarn.lock ./
RUN yarn install --production
COPY . .
CMD ["node", "src/index.js"]
2. В каталоге, где находится Dockerfile, создайте файл .dockerignore с таким содержанием:
node_modules
файлы .dockerignore – это простой способ выборочного копирования только файлов, относящихся к изображениям. Вы можете прочитать больше об этом здесь. В этом случае папка node_modules должна быть опущена на втором шаге COPY, поскольку в противном случае она, возможно, перезапишет файлы, которые были созданы командой на шаге RUN. Для получения более подробной информации о том, почему это рекомендуется для приложений Node.js и других передовых практик, ознакомьтесь с их руководством по настройке Node.js веб-приложений.
3. Создайте новый образ с помощью docker build.
docker build -t getting-started .
Вы должны увидеть вывод, подобный этому…
[+] Building 16.1s (10/10) FINISHED
=> [internal] load build definition from Dockerfile
=> => transferring dockerfile: 175B
=> [internal] load .dockerignore
=> => transferring context: 2B
=> [internal] load metadata for docker.io/library/node:18-alpine
=> [internal] load build context
=> => transferring context: 53.37MB
=> [1/5] FROM docker.io/library/node:18-alpine
=> CACHED [2/5] WORKDIR /app
=> [3/5] COPY package.json yarn.lock ./
=> [4/5] RUN yarn install --production
=> [5/5] COPY . .
=> exporting to image
=> => exporting layers
=> => writing image sha256:d6f819013566c54c50124ed94d5e66c452325327217f4f04399b45f94e37d25
=> => naming to docker.io/library/getting-started
Вы увидите, что все слои были перестроены. Совершенно нормально, так как мы немного изменили файл Dockerfile.
4. Теперь внесите изменения в src/static/index.html файл (например, измените
5. Создайте образ Docker прямо сейчас, снова используя docker build -t getting-started .. На этот раз ваш результат должен выглядеть немного по-другому.
[+] Building 1.2s (10/10) FINISHED
=> [internal] load build definition from Dockerfile
=> => transferring dockerfile: 37B
=> [internal] load .dockerignore
=> => transferring context: 2B
=> [internal] load metadata for docker.io/library/node:18-alpine
=> [internal] load build context
=> => transferring context: 450.43kB
=> [1/5] FROM docker.io/library/node:18-alpine
=> CACHED [2/5] WORKDIR /app
=> CACHED [3/5] COPY package.json yarn.lock ./
=> CACHED [4/5] RUN yarn install --production
=> [5/5] COPY . .
=> exporting to image
=> => exporting layers
=> => writing image sha256:91790c87bcb096a83c2bd4eb512bc8b134c757cda0bdee4038187f98148e2eda
=> => naming to docker.io/library/getting-started
Во-первых, вы должны заметить, что сборка была НАМНОГО быстрее! И вы увидите, что в нескольких шагах используются ранее кэшированные слои. Итак, ура! Мы используем кэш сборки. Передача и прием этого изображения и его обновления также будут намного быстрее. Ура!
Многоступенчатые сборки
Хотя мы не собираемся слишком углубляться в это в этом руководстве, многоступенчатые сборки - невероятно мощный инструмент, помогающий использовать несколько этапов для создания изображения. У них есть такие преимущества:
-
Отделиние зависимостей, используемых во время сборки, от зависимостей времени выполнения
-
Уменьшение общего размера изображения, чтобы отправлять только то, что необходимо вашему приложению для запуска.
Пример Maven/Tomcat
При создании приложений на базе Java необходим JDK для компиляции исходного кода в байт-код Java. Однако этот JDK не нужен в производстве. Кроме того, вы можете использовать такие инструменты, как Maven или Gradle, чтобы помочь в создании приложения. Они также не нужны в нашем окончательном изображении. Многоступенчатые сборки помогают.
# syntax=docker/dockerfile:1
FROM maven AS build
WORKDIR /app
COPY . .
RUN mvn package
FROM tomcat
COPY --from=build /app/target/file.war /usr/local/tomcat/webapps
В этом примере мы используем одну стадию (называемую build) для выполнения фактической сборки Java с использованием Maven. На второй стадии (начиная с FROM tomcat) мы копируем файлы со стадии сборки. Окончательное изображение - это только последняя создаваемая стадия (которая может быть переопределена с помощью флага --target).
Пример React
При создании приложений React нам нужна среда Node.js для компиляции кода JS (обычно JSX), таблиц стилей SASS и многого другого в статический HTML, JS и CSS. Если мы не выполняем рендеринг на стороне сервера, нам даже не нужна среда Node.js для нашей производственной сборки. Почему бы не отправить статические ресурсы в статический контейнер nginx?
# syntax=docker/dockerfile:1
FROM node:18 AS build
WORKDIR /app
COPY package* yarn.lock ./
RUN yarn install
COPY public ./public
COPY src ./src
RUN yarn run build
FROM nginx:alpine
COPY --from=build /app/build /usr/share/nginx/html
Здесь мы используем изображение node:18 для выполнения сборки (максимальное кэширование слоев), а затем копируем выходные данные в контейнер nginx. Круто, да?
Следующие шаги
Немного разбираясь в структуре изображений, вы сможете создавать изображения быстрее и вносить меньше изменений. Сканирование изображений дает вам уверенность в том, что контейнеры, которые вы запускаете и распространяете, безопасны. Многоступенчатые сборки также помогают уменьшить общий размер изображения и повысить безопасность конечного контейнера, отделяя зависимости во время сборки от зависимостей во время выполнения.
В следующем разделе вы узнаете о дополнительных ресурсах, которые вы можете использовать для продолжения изучения контейнеров.