6. Партиции, Представления, и Другие Объекты Схемы
Хотя таблицы и индексы являются наиболее важными и часто используемыми объектами схемы, база данных поддерживает множество других типов объектов схемы, наиболее распространенные из которых обсуждаются в этой главе.
Обзор партиционирования
В БД Oracle партиционирование позволяет разбивать очень большие таблицы и индексы на более мелкие и управляемые части, называемые партициями. Каждая партиция представляет собой независимый объект со своим собственным именем и, возможно, собственными характеристиками хранилища.
Для аналогии, иллюстрирующей партиционирование, предположим, что у менеджера по персоналу есть один большой ящик, содержащий папки сотрудников. В каждой папке указана дата найма сотрудника. Запросы часто делаются по сотрудникам, нанятым в определенном месяце. Одним из подходов к удовлетворению таких запросов является создание индекса по дате найма сотрудника, который указывает расположение папок, разбросанных по всему ящику. В отличие от этого, стратегия партиционирования использует множество ячеек меньшего размера, причем каждая ячейка содержит папки для сотрудников, нанятых в данном месяце.
Использование коробок меньшего размера имеет ряд преимуществ. Когда менеджера по персоналу попросят получить папки для сотрудников, принятых на работу в июне, он может просто взять июньский ящик. Кроме того, если какая-либо маленькая коробка временно повреждена, другие маленькие коробки остаются доступными. Перемещение офисов также становится проще, потому что вместо перемещения одной тяжелой коробки менеджер может переместить несколько небольших коробок.
С точки зрения приложения существует только один объект схемы. Инструкции SQL не требуют никаких изменений для доступа к партиционированным таблицам. Партиционирование полезно для многих различных типов приложений БД, особенно для тех, которые управляют большими объемами данных.
Преимущества заключаются в следующем:
-
В повышении доступности
Недоступность партиции не влечет за собой недоступность объекта. Оптимизатор запросов автоматически удаляет партиции, на которые нет ссылок, из плана запросов, чтобы на запросы не влияли, когда партиции недоступны. -
В упрощении администрирования объектов схемы
Партиционированный объект состоит из частей, которыми можно управлять как коллективно, так и по отдельности. Инструкции DDL могут управлять партициями, а не целыми таблицами или индексами. Таким образом, вы можете разбить ресурсоемкие задачи, такие как перестройка индекса или таблицы. Например, вы можете перемещать по одной партиции таблицы за раз. Если возникает проблема, то необходимо повторить только перемещение партиции, а не перемещение таблицы. Кроме того, удаление партиции позволяет избежать выполнения многочисленных инструкций DELETE. -
В уменьшении конкуренции за общие ресурсы в системах OLTP
В некоторых системах OLTP партиции могут уменьшить конкуренцию за общий ресурс. Например, DML распределен по многим сегментам, а не по одному сегменту. -
В повышеннии производительности в запросах для хранилищ данных
В хранилище данных партиционирование может ускорить обработку специальных запросов. Например, таблицу продаж, содержащую миллион строк, можно разделить по кварталам.
Характеристики партиции
Каждая партиция таблицы или индекса должна иметь одинаковые логические атрибуты, такие как имена столбцов, типы данных и ограничения. Например, все партиции таблицы используют одни и те же определения столбцов и ограничений.
Однако каждая партиция может иметь отдельные физические атрибуты, такие как табличное пространство, к которому она принадлежит.
Ключ партиции
Ключ партиции – это набор из одного или нескольких столбцов, который определяет партицию, в которую должна входить каждая строка в партиционированной таблице. Каждая строка однозначно назначается одной партиции.
В таблице sales (продажи) вы могли бы указать столбец time_id в качестве ключа партиции диапазона. БД присваивает строки партициям в зависимости от того, попадает ли дата в этом столбце в указанный диапазон. БД Oracle автоматически направляет операции вставки, обновления и удаления в соответствующую партицию с помощью ключа партиции.
Стратегии партиционирования
Oracle предлагает несколько стратегий партиционирования, которые управляют тем, как БД размещает данные в партициях. Основными стратегиями являются разделение по диапазону, списку и хэшу.
Одноуровневое партиционирование использует только один метод распределения данных, например, разбиение только на списки или только на диапазоны. При составном партиционировании таблица разбивается на партиции с помощью одного метода распределения данных, а затем каждая партиция дополнительно делится на подпартиции с использованием второго метода распределения данных. Например, вы могли бы использовать списочное партиционирование для channel_id и диапазонное партиционирование для time_id.
Пример 6-1 Пример набора строк для секционированной таблицы
В этом примере партиционирования предполагается, что вы хотите заполнить партиционированную таблицу sales следующими строками:
PROD_ID CUST_ID TIME_ID CHANNEL_ID PROMO_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- --------- ---------- ---------- ------------- -----------
116 11393 05-JUN-99 2 999 1 12.18
40 100530 30-NOV-98 9 33 1 44.99
118 133 06-JUN-01 2 999 1 17.12
133 9450 01-DEC-00 2 999 1 31.28
36 4523 27-JAN-99 3 999 1 53.89
125 9417 04-FEB-98 3 999 1 16.86
30 170 23-FEB-01 2 999 1 8.8
24 11899 26-JUN-99 4 999 1 43.04
35 2606 17-FEB-00 3 999 1 54.94
45 9491 28-AUG-98 4 350 1 47.45
Диапазонное партиционирование (Range)
При диапазонном партиционировании БД сопоставляет партиционируемые строки на основании диапазона значений ключа партиционирования. Диапазонное партиционирование является наиболее распространенным типом партиционирования и часто используется с датами.
Предположим, что вы создаете time_range_sales в виде партиционированной таблицы, используя следующую инструкцию SQL, со столбцом time_id в качестве ключа партиционирования:
CREATE TABLE time_range_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY RANGE (time_id)
(PARTITION SALES_1998 VALUES LESS THAN (TO_DATE('01-JAN-1999','DD-MON-YYYY')),
PARTITION SALES_1999 VALUES LESS THAN (TO_DATE('01-JAN-2000','DD-MON-YYYY')),
PARTITION SALES_2000 VALUES LESS THAN (TO_DATE('01-JAN-2001','DD-MON-YYYY')),
PARTITION SALES_2001 VALUES LESS THAN (MAXVALUE)
);
После этого вы загружаете time_range_sales со строками из примера 6-1. Код показывает распределение строк по четырем партициям. БД выбирает партицию для каждой строки на основе значения time_id в соответствии с правилами, указанными в предложении PARTITION BY RANGE. Значение ключа партиционирования диапазона определяет не включающую верхнюю границу для указанной партиции.
Интервальное партиционирование (Interval)
Интервальное партиционирование – является расширением диапазонного.
Если вы вставляете данные, которые превышают существующие партиции диапазона, то БД Oracle автоматически создает партиции с указанным интервалом. Например, вы могли бы создать таблицу истории продаж, в которой данные за каждый месяц хранятся в отдельной партиции.
Интервальное партиционирование позволяет избежать явного создания интервальных партиций. Можно использовать интервальное партиционирование практически для каждой таблицы, которая партиционирована по диапазонам и использует фиксированные интервалы для новых партиций. Если вы не создаете диапазонные партиции с разными интервалами или если вы всегда не задаете определенные атрибуты партиций, рассмотрите возможность использования интервальных партиций.
При интервальном партиционировании необходимо указать хотя бы одну партицию диапазона. Значение ключа партиционирования диапазона определяет максимальное значение партиции диапазона, которое называется точкой перехода. БД автоматически создает интервальные партиции для данных со значениями, которые находятся за пределами точки перехода. Нижняя граница каждого интервального партиционирования является включающей верхней границей предыдущего диапазона или интервальной партиции. Таким образом, в примере 6-2 значение 01-JAN-2011 находится в партиции p2.
БД создает интервальные партиции для данных за пределами точки перехода. Интервальное партиционирование расширяет партиционирование по диапазонам, предоставляя БД указание создавать партиции с указанным диапазоном или интервалом. БД автоматически создает партиции, когда данные, вставленные в таблицу, превышают все существующие партиции диапазона. В примере 6-2 раздел p3 содержит строки со значениями time_id ключа партиции, большими или равными 01-JAN-2013.
Пример 6-2 Интервальное партиционирование
Предположим, что вы создаете таблицу продаж с четырьмя партициями разной ширины. Вы указываете, что выше точки перехода 1 января 2013 года БД должна создавать партиции с интервалом в один месяц. Верхняя граница партиции p3 представляет собой точку перехода. Партиция p3 и все партиции под ней находятся в партициях диапазона, тогда как все партиции над ней попадают в партиции интервала.
CREATE TABLE interval_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY RANGE (time_id)
INTERVAL(NUMTOYMINTERVAL(1, 'MONTH'))
( PARTITION p0 VALUES LESS THAN (TO_DATE('1-1-2010', 'DD-MM-YYYY'))
, PARTITION p1 VALUES LESS THAN (TO_DATE('1-1-2011', 'DD-MM-YYYY'))
, PARTITION p2 VALUES LESS THAN (TO_DATE('1-7-2012', 'DD-MM-YYYY'))
, PARTITION p3 VALUES LESS THAN (TO_DATE('1-1-2013', 'DD-MM-YYYY')) );
Вы добавляете продажу, совершенную 10 октября 2014 года:
SQL> INSERT INTO interval_sales VALUES (39,7602,'10-OCT-14',9,null,1,11.79);
1 row created.
Запрос USER_TAB_PARTITIONS показывает, что БД создала новую партицию для продажи 10 октября, поскольку дата продажи была позже точки перехода:
SQL> COL PNAME FORMAT a9
SQL> COL HIGH_VALUE FORMAT a40
SQL> SELECT PARTITION_NAME AS PNAME, HIGH_VALUE
2 FROM USER_TAB_PARTITIONS WHERE TABLE_NAME = 'INTERVAL_SALES';
PNAME HIGH_VALUE
--------- ----------------------------------------
P0 TO_DATE(' 2007-01-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
P1 TO_DATE(' 2008-01-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
P2 TO_DATE(' 2009-07-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
P3 TO_DATE(' 2010-01-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P1598 TO_DATE(' 2014-11-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
Списочное партиционирование (List)
При списочном партиционировании БД использует список дискретных значений в качестве ключа партиционирования для каждой партиции. Ключ партиционирования состоит из одного или нескольких столбцов.
Можно использовать списочное партиционирование, чтобы управлять тем, как отдельные строки соотносятся с определенными партициями. Используя списки, можно группировать и упорядочивать связанные наборы данных, когда ключ, используемый для их идентификации, не упорядочен удобным образом.
Пример 6-3 Списочное партиционирование
Предположим, что вы создаете list_sales в виде таблицы со списочным партиционированием, используя следующий оператор, где столбец channel_id является ключом партиции:
CREATE TABLE list_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY LIST (channel_id)
( PARTITION even_channels VALUES ('2','4'),
PARTITION odd_channels VALUES ('3','9')
);
После этого вы загружаете таблицу со строками из примера 6-1. Код показывает распределение строк в двух партициях. БД выбирает партицию для каждой строки на основе значения channel_id в соответствии с правилами, указанными в предложении PARTITION BY LIST. Строки со значением channel_id, равным 2 или 4, хранятся в партиции EVEN_CHANNELS, в то время как строки со значением channel_id, равным 3 или 9, хранятся в партиции ODD_CHANNELS.
Хэшированное партиционирование (Hash)
При хэш-партиционировании БД сопоставляет строки с партициями на основе алгоритма хэширования, который БД применяет к указанному пользователем ключу партиционирования.
Назначение строки определяется внутренней хэш-функцией, применяемой к строке базой данных. Когда количество разделов равно степени 2, алгоритм хеширования создает примерно равномерное распределение строк по всем партициям.
Хэш-партиционирование полезно для разделения больших таблиц для повышения управляемости. Вместо одной большого таблицы, которой нужно управлять, у вас есть несколько частей поменьше. Потеря одной хэш-партиции не влияет на остальные партиции и может быть восстановлена независимо. Хэш-партиционирование также полезно в системах OLTP с высокой конкуренцией за обновления. Например, сегмент разделен на несколько частей, каждая из которых обновляется, вместо одного сегмента, который испытывает конфликт.
Предположим, что вы создаете партиционированную таблицу hash_sales, используя следующий оператор, со столбцом prod_id в качестве ключа партиционирования:
CREATE TABLE hash_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY HASH (prod_id)
PARTITIONS 2;
После этого вы загружаете таблицу со строками из примера 6-1. Код показывает возможное распределение строк в двух партициях. Имена этих партиций генерируются системно.
Когда вы вставляете строки, БД пытается случайным образом и равномерно распределить их по партициям. Вы не можете указать партицию, в которую помещается строка. БД применяет хэш-функцию, результат которой определяет, какая партиция содержит строку.
Ссылочное партиционирование (Reference)
При ссылочном партиционировании стратегия партиционирования дочерней таблицы определяется исключительно через связь внешнего ключа с родительской таблицей. Для каждой партиции в родительской таблице в дочерней таблице существует ровно одна соответствующая партиция. Родительская таблица хранит родительские записи в определенной партиции, а дочерняя таблица хранит дочерние записи в соответствующей партиции.
Например, таблица orders является родительской для таблицы line_items, с первичным ключом и внешним ключом, определенными для order_id. Таблицы партиционированы ссылочно. Например, если БД хранит заказ 233 в партиции Q3_2015 таблицы orders, то БД хранит все позиции для заказа 233 в партиции Q3_2015 для line_items. Если партиция Q4_2015 добавлена в таблице orders, то БД автоматически добавляет Q4_2015 в таблице line_items.
Преимуществами ссылочного партиционирования являются:
-
Используя одну и ту же стратегию партиционирования как для родительской, так и для дочерней таблиц, вы избегаете дублирования всех ключевых столбцов партиционирования. Эта стратегия уменьшает накладные расходы, связанные с денормализацией вручную, и экономит место.
-
Операции обслуживания родительской таблицы выполняются в дочерней таблице автоматически. Например, когда вы добавляете партицию в главную таблицу, БД автоматически распространяет это добавление на своих потомков.
-
БД автоматически использует разумное соединение партиций родительской и дочерней таблиц, что повышает производительность.
Вы можете использовать ссылочное партиционирование со всеми базовыми стратегиями партиционирования, включая интервальное. Также можно создавать ссылочные партиционированные таблицы в виде составных партиций.
Пример 6-4 Создание ссылочно-партиционированных таблиц
В этом примере создается родительская таблица orders, диапазонно-партиционированная по order_date. Ссылочно-партиционированная дочерняя таблица order_items, создается с четырьмя партициями, Q1_2015, Q2_2015, Q3_2015 и Q4_2015, где каждая партиция содержит строки order_items, соответствующие заказам в соответствующих родительских партициях.
CREATE TABLE orders
( order_id NUMBER(12),
order_date DATE,
order_mode VARCHAR2(8),
customer_id NUMBER(6),
order_status NUMBER(2),
order_total NUMBER(8,2),
sales_rep_id NUMBER(6),
promotion_id NUMBER(6),
CONSTRAINT orders_pk PRIMARY KEY(order_id)
)
PARTITION BY RANGE(order_date)
( PARTITION Q1_2015 VALUES LESS THAN (TO_DATE('01-APR-2015','DD-MON-YYYY')),
PARTITION Q2_2015 VALUES LESS THAN (TO_DATE('01-JUL-2015','DD-MON-YYYY')),
PARTITION Q3_2015 VALUES LESS THAN (TO_DATE('01-OCT-2015','DD-MON-YYYY')),
PARTITION Q4_2015 VALUES LESS THAN (TO_DATE('01-JAN-2006','DD-MON-YYYY'))
);
CREATE TABLE order_items
( order_id NUMBER(12) NOT NULL,
line_item_id NUMBER(3) NOT NULL,
product_id NUMBER(6) NOT NULL,
unit_price NUMBER(8,2),
quantity NUMBER(8),
CONSTRAINT order_items_fk
FOREIGN KEY(order_id) REFERENCES orders(order_id)
)
PARTITION BY REFERENCE(order_items_fk);
Составное партиционирование (Composite)
При составном партиционировании таблица разбивается на партиции с помощью одного метода распределения данных, а затем каждая партиция дополнительно подразделяется на подпартиции с использованием второго метода распределения данных. Таким образом, составное партиционирование сочетает в себе основные методы распределения данных. Все подпартиции для данной партиции представляют собой логическое подмножество данных.
Составное партиционирование обеспечивает ряд преимуществ:
-
В зависимости от инструкции SQL сокращение партиции по одному или двум измерениям может повысить производительность.
-
Запросы могут иметь возможность использовать полные или частичные объединения партиций в любом измерении.
-
Можно выполнять параллельное резервное копирование и восстановление одной таблицы.
-
Количество секций больше, чем при одноуровневом партиционировании, что может быть выгодно для параллельного выполнения.
-
Можно реализовать скользящее окно для поддержки исторических данных и по-прежнему разбивать на партиции в другом измерении, если многие инструкции могут извлечь выгоду из сокращения партиций или соединения партиций.
-
Можно хранить данные по-разному, основываясь на идентификации с помощью ключа партиционоривания. Например, вы можете принять решение сохранить данные для определенного типа продукта в сжатом формате, доступном только для чтения, и сохранить данные о других типах продуктов несжатыми.
Разбиение на диапазоны, списки и хэш-функции допустимо в качестве стратегий партиционирования на подпартиции для составных партиционированных таблиц. На следующем рисунке представлено графическое представление составных партиций range-hash и range-list.
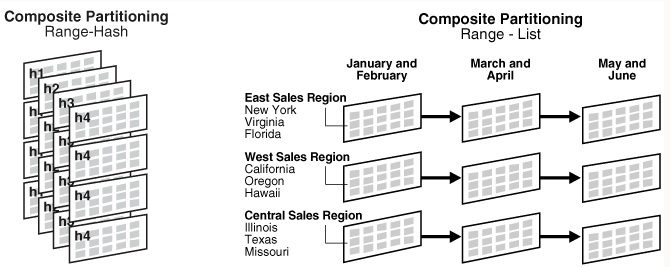
БД хранит каждую подпартицию в составной партиционированной таблице в виде отдельного сегмента. Таким образом, свойства подпартиций могут отличаться от свойств таблицы или партиций, к которому принадлежат подпартиции.
Партиционированные таблицы
Партиционированная таблица состоит из одной или нескольких партиций, которые управляются индивидуально и могут работать независимо от других партиций.
Таблица может быть либо партиционированной, либо непартиционированной. Даже если партиционированная таблица состоит только из одной партиции, эта таблица отличается от непартиционированной таблицы без разделов, к которой нельзя добавлять партиции.
Сегменты партиционированной таблицы
Партиционированная таблица состоит из одного или нескольких сегментов табличной партиции.
Если вы создаете партиционированную таблицу с именем hash_products, для этой таблицы не выделяется табличный сегмент. Вместо этого БД сохраняет данные каждой табличной партиции в своем собственном сегменте партиции. Каждый сегмент табличной партиции содержит часть табличных данных.
Когда партиционирована внешняя таблица, все партиции находятся вне БД. В гибридной партиционированной таблице некоторые партиции хранятся в виде сегментов, в то время как другие хранятся извне. Например, некоторые партиции таблицы продаж могут храниться в файлах данных, а другие – в электронных таблицах.
Сжатие партиционированных таблиц
Некоторые или все разделы таблицы, организованной в куче, можно сохранять в сжатом формате.
Сжатие экономит место и может ускорить выполнение запроса. По этой причине сжатие может быть полезно в таких средах, как хранилища данных, где объем операций вставки и обновления невелик, а также в средах OLTP.
Можно объявить атрибуты сжатия для табличного пространства, таблицы или партиции. Если сжатие объявлено на уровне табличного пространства, то таблицы, созданные в табличном пространстве, сжимаются по умолчанию. Можно изменить атрибут сжатия для таблицы, и в этом случае изменение применяется только к новым данным, поступающим в эту таблицу. Следовательно, одна таблица или партиция могут содержать сжатые и несжатые блоки, что гарантирует, что размер данных не увеличится из-за сжатия. Если сжатие может увеличить размер блока, то БД не применяет его к блоку.
Партиционированные индексы
Партиционированный индекс – это индекс, который, подобно партиционированной таблице, был разделен на более мелкие и управляемые части.
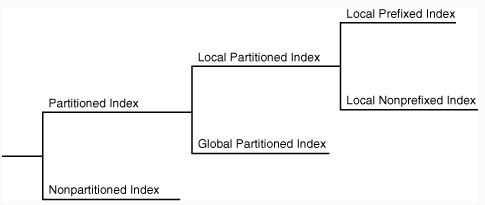
Глобальные индексы разбиваются на партиции, независимо от таблицы, для которой они созданы, в то время как локальные индексы автоматически привязываются к методу разбиения таблицы на партиции. Подобно партиционированным таблицам, партиционированные индексы улучшают управляемость, доступность, производительность и масштабируемость.
На следующем рисунке показаны параметры партиционированния индекса.
Локальные партиционированные индексы
В локальном партиционированном индексе индекс разбит на те же столбцы, с тем же количеством партиций и теми же границами партиций, что и его таблица.
Каждая индексная партиция связана ровно с одной партицией базовой таблицы, так что все ключи индексной партиции относятся только к строкам, хранящимся в одной табличной партиции. Таким образом, БД автоматически синхронизирует индексные партиции со связанными с ними табличными партициями, делая каждую пару таблица-индекс независимой.
Локальные партиционированные индексы широко распространены в средах хранилищ данных. Локальные индексы обладают следующими преимуществами:
-
Повышается доступность, поскольку действия, которые приводят к недействительности или недоступности данных в партиции, влияют только на эту партицию.
-
Упрощается обслуживание партиций. При перемещении табличной партиции или при устаревании данных партиции необходимо перестраивать или поддерживать только связанную с ней локальную индексную партицию. В глобальном индексе все индексные партиции должны быть перестроены или поддерживаться в рабочем состоянии.
-
Если происходит восстановление партиции на определенный момент времени, то индексы могут быть восстановлены до времени восстановления (см. Руководство пользователя Oracle Database Backup and Recovery). Весь индекс не нужно перестраивать заново.
В примере с хэш-партиционированием показана инструкция создания для партиционированной таблицы hash_sales, использующая столбец prod_id в качестве ключа партиционирования. В следующем примере создается локальный партиционированный индекс по столбцу time_id таблицы hash_sales:
CREATE INDEX hash_sales_idx ON hash_sales(time_id) LOCAL;
На рисунке 6-3 таблица hash_products имеет два партиции, поэтому и hash_sales_index имеет две партиции. Каждая индексная партиция связана с другой табличной партицией. Индексная партиция SYS_P38 индексирует строки в табличной партиции SYS_P33, тогда как индексная партиция SYS_P39 индексирует строки в табличной партиции SYS_P34.
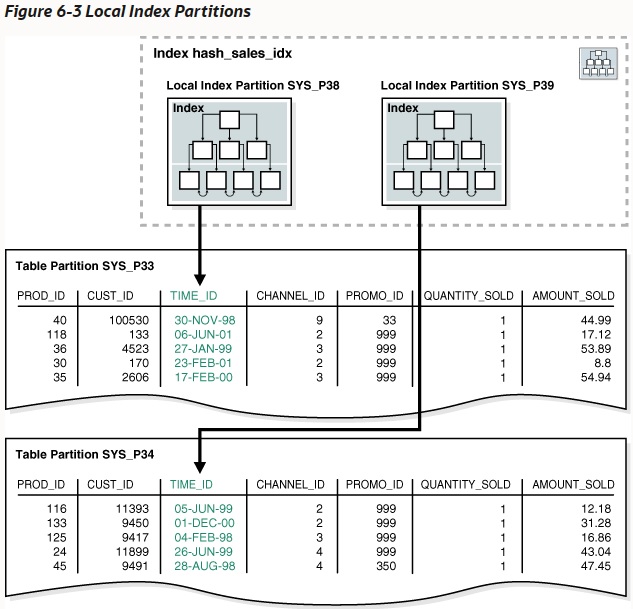
Вы не можете добавить партицию в локальный индекс явно. Вместо этого новые партиции добавляются в локальные индексы только тогда, когда вы добавляете партицию в базовую таблицу. Аналогично, вы не можете явно удалить партицию из локального индекса. Вместо этого локальные индексные партиции удаляются только тогда, когда вы удаляете партицию из базовой таблицы.
Как и другие индексы, для партиционированных таблиц можно создать растровый индекс. Единственное ограничение заключается в том, что растровые индексы для партиционированной таблицы должны быть локальными – они не могут быть глобальными индексами. Глобальные растровые индексы поддерживаются только в непартиционированных таблицах.
Локальные префиксные и непрефиксные индексы
Локальные партиционированные индексы могут быть либо префиксные, либо непрефиксные.
Подтипы индекса определяются следующим образом:
-
Локальные префиксные индексы
В этом случае ключи партиционирования находятся на переднем месте определения индекса. В примереtime_range_salesпри диапазонном партиционировании таблица партиционируется по диапазону поtime_id. Локальный префиксный индекс этой таблицы будет иметьtime_idв качестве первого столбца в своем списке. -
Локальные непрефиксные индексы
В этом случае ключи партиционирования не находятся на переднем месте списка индексированных столбцов и вообще не должны быть в списке. В примереhash_sales_idxв локальных партиционированных индексах индекс является локальным непрефиксным, поскольку ключ партиционированияproduct_idне находится на переднем месте.
Оба типа индексов могут использовать преимущества исключения партиций (также называемого сокращением партиций), которое происходит, когда оптимизатор ускоряет доступ к данным, исключая партиции из рассмотрения. Может ли запрос удалять партиции, зависит от предиката запроса. Запрос, использующий локальный префиксный индекс, всегда допускает исключение индексной партиции, в то время как запрос, использующий локальный непрефиксный индекс, может этого и не делать.
Хранение локальные индексных партиций
Как и табличная партиция, локальная индексная партиция хранится в своем собственном сегменте. Каждый сегмент содержит часть общих данных индекса. Таким образом, локальный индекс, состоящий из четырех партиций, хранится не в одном индексном сегменте, а в четырех отдельных сегментах.
Глобальные партиционированные индексы
Глобальный партиционированный индекс – это индекс B-дерева, который партиционируется независимо от базовой таблицы, на основе которой он создан. Отдельная индексная партиция может указывать на любую или на все табличные партиции, тогда как в локально партиционированном индексе существует соотношение “один-к-одному” между индексными партициями и табличными партициями.
В целом, глобальные индексы полезны для приложений OLTP, где важны быстрый доступ, целостность данных и доступность. В системе OLTP таблица может быть партиционирована по одному ключу, например, по столбцу employees.department_id, но приложению может потребоваться доступ к данным с помощью множества разных ключей, например, по employee_id или job_id. Глобальные индексы могут быть полезны в этом сценарии.
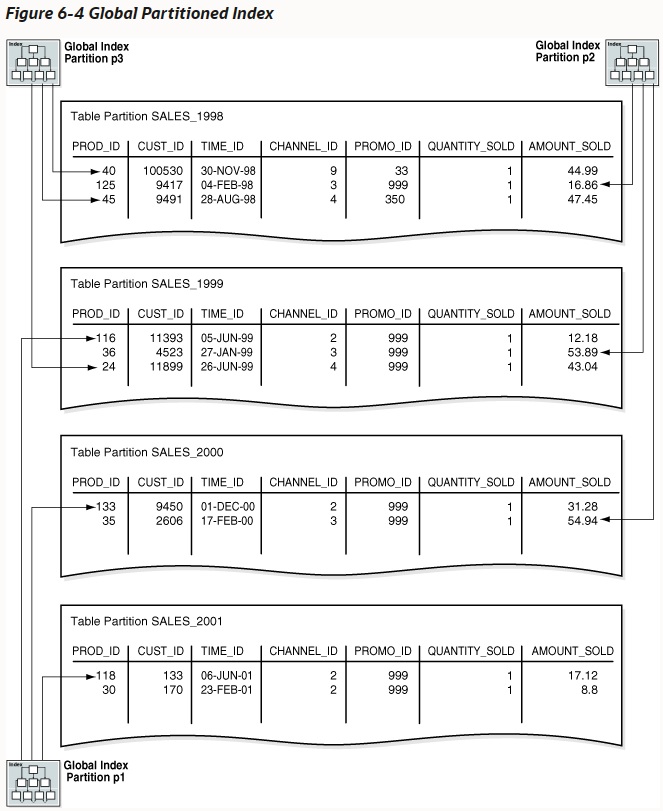
В качестве иллюстрации предположим, что вы создаете глобальный партиционированный индекс в таблице time_range_sales из раздела “Диапазонное партиционирование”. В этой таблице строки для продаж за 1998 год хранятся в одной партиции, строки для продаж за 1999 год – в другой и так далее. В следующем примере создается глобальный индекс, партиционированный по диапазону, по столбцу channel_id:
CREATE INDEX time_channel_sales_idx ON time_range_sales (channel_id)
GLOBAL PARTITION BY RANGE (channel_id)
(PARTITION p1 VALUES LESS THAN (3),
PARTITION p2 VALUES LESS THAN (4),
PARTITION p3 VALUES LESS THAN (MAXVALUE));
Как показано на рис. 6-4, партиция глобального индекса может содержать записи, указывающие на несколько табличных партиций. Индексная партиция p1 указывает на строки с channel_id = 2, индексная партиция p2 указывает на строки с channel_id = 3, а индексная партиция p3 указывает на строки с channel_id in (4, 9).
Частичные индексы для партиционированных таблиц
Частичный индекс – это индекс, который коррелирует со свойствами индексации связанной партиционированной таблицы.
Корреляция позволяет указать, какие партиции таблицы индексируются. Частичные индексы обеспечивают следующие преимущества:
-
Табличные партиции, которые не индексируются, позволяют избежать использования ненужного пространства для хранения индексов.
-
Может улучшить производительность загрузок и запросов.
До Oracle Database 12c операция разделенияexchangeтребовала физического обновления связанного глобального индекса, чтобы сохранить его пригодным для использования. Начиная с Oracle Database 12c, если партиции, участвующие в операции обслуживания партиций, не являются частью частичного глобального индекса, то индекс остается пригодным для использования, не требуя какого-либо обслуживания. -
Если при создании индекса индексируются только некоторые табличные партиции, и если позже проиндексируете другие, то можно уменьшить пространство сортировки, требуемое при создании индекса.
Можно включить или отключить индексацию для отдельных табличных партиций. Частичный локальный индекс не содержит используемых индексных партиций для всех табличных партиций, у которых отключена индексация. Глобальный индекс, независимо от того, партиционирован он или нет, исключает данные из всех партиций, индексация которых отключена. БД не поддерживает частичные индексы для индексов, которые накладывают уникальные ограничения.
На рисунке 6-5 показан тот же глобальный индекс, что и на рисунке 6-4, за исключением того, что глобальный индекс является частичным. Для табличных партиций SALES_1998 и SALES_2000 свойство индексации установлено в значение OFF, поэтому частичный глобальный индекс их не индексирует.
